Historians Can Predict the Future

Photo taken while hiking Los Leones Trail in Santa Monica, CA.
View the entire project on Github here.
Background
History, present, future.
People often ask me “Why?” when they learn I studied History during my undergraduate degree. Studying history taught me how to identify patterns—an essential skill for understanding the past to predict the future. History tends to have a habit of repeating itself.
This same logic applies to Machine Learning. Training, testing, and predicting mirror the process of analyzing historical events. Prediction models excite me because they follow this logic, allowing me to uncover patterns and insights from data. For this project, I built and compared several prediction models using different methods and tools to evaluate their accuracy. I also see this as a layer in the "multi-layered cake" of my future research projects.
Inspiration
I was inspired by a project I completed in grad school, where I developed a Naive Bayes classifier for Jeopardy! questions. As I wanted to challenge myself, I aimed to create improved models and take my skills to the next level. You can find my old project here.
The Models
I started by loading a customer review dataset from Kaggle into a Jupyter notebook. After cleaning the data, I categorized the reviews into three groups:
High (scores 4–5)
Neutral (score 3)
Negative (scores 1–2)
I then mapped these categories numerically to prepare the data for training.

Exploring the dataset revealed that it was heavily imbalanced—67% of the reviews were positive. While this imbalance presented a challenge, I welcomed the opportunity to learn from it.

Each model followed a similar pipeline for data cleaning and preparation, but the training and prediction methods grew progressively more advanced:
Naive Bayes Classifier (Basic)
My first model was a simple Naive Bayes classifier that predicted review sentiment based solely on the words in the review.Naive Bayes Classifier with Scikit-learn
For the second model, I leveraged Scikit-learn to introduce additional features, such as weighting words based on their importance, which improved the model's accuracy.TensorFlow Neural Network
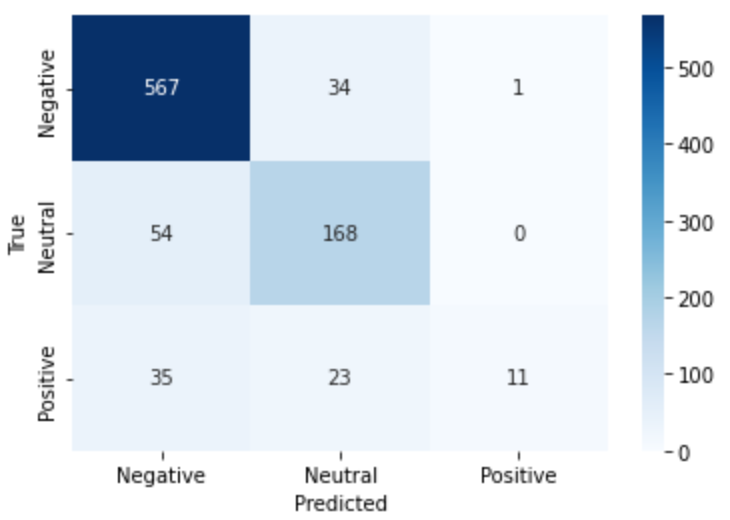
My third and most advanced model utilized TensorFlow to implement a neural network. This approach further refined the predictions and significantly increased the accuracy.
Prediction Model 1: 68% Accurate

Prediction Model 2: 72% Accurate

Prediction Model 3: 84% Accurate

Results and Reflections
The TensorFlow model achieved an accuracy of 84%, which was a notable improvement over the earlier models. However, I believe there’s still room for optimization. For instance, retaining emoji characters during data preprocessing might enhance predictions, as certain emojis convey clear sentiment (e.g., a smiley face correlating with a positive review).
This project not only allowed me to practice building and comparing models but also highlighted the importance of thoughtful preprocessing and feature selection in handling imbalanced datasets. It’s a small but meaningful step toward my broader goal of mastering Machine Learning and creating impactful solutions.
Model 2 Confusion Matrix

Model 3 Confusion Matrix
Keep checking my blog to see how this project progresses.
- Mali